【Tidyverse优雅编程】Bootstrap残差法回归估计 |
您所在的位置:网站首页 › r语言 求方差 › 【Tidyverse优雅编程】Bootstrap残差法回归估计 |
【Tidyverse优雅编程】Bootstrap残差法回归估计
|
问题来自 tidy-R语言2 群,先是陈小狐问到残差重抽样法,然后我搜到一篇 SAS 官网文章: 接着,又有稳住根据该文章,写了个R实现,只是代码是用 for 循环逐个组装 10 万级别的数,代码啰嗦,速度又慢。所以,我来了个tidyverse 优雅数据思维编程的改写。 1 Bootstrap 残差法步骤(1) 拟合一个 Y 关于 X 的线性回归模型,保存预测值( Y_{Pred} )和残差值( R ); (2) Bootstrap 样本,生成包括形成一个新的响应向量: Y_{i, Boot} = Y_{i, Pred} + R_{rand} ,其中 Y_{i, Pred} 是第 i 个预测值, R_{rand} 是从第 (1) 步的残差中随机选择的(有替换)。创建 B 个样本,其中 B 是一个大数; (3) 对于每个 Bootstrap 样本,拟合 Y_{Boot} 关于 X 的回归模型。 (4) 第 (3) 步计算的所有统计量合起来构成 Bootstrap 分布,用来估计标准误和参数的置信区间。 2 整洁 R 实现2.1 准备示例数据library(tidyverse) df = tibble( ID = 1:19, weight = c(50.5,77,84,83,85,99.5,84.5,112.5,84,102.5,102.5,90,128, 98,112,112,133,112.5,150), height = c(51.3,56.3,56.5,57.3,57.5,59,59.8,62.5,62.5,62.8,63.5,64.3,64.8,65.3,66.5,66.5,67,69,72)) df 2.2 初始线性回归,保存需要的数据fit_lm = lm(weight ~ height, df)
b = coef(fit_lm) # 原始回归系数
b 2.2 初始线性回归,保存需要的数据fit_lm = lm(weight ~ height, df)
b = coef(fit_lm) # 原始回归系数
b # 用于Bootstrap的残差和预测值
res = tibble(
ID = 1:19,
resid = fit_lm$residuals,
pred = fit_lm$fitted.values)
res # 用于Bootstrap的残差和预测值
res = tibble(
ID = 1:19,
resid = fit_lm$residuals,
pred = fit_lm$fitted.values)
res 2.3 重抽样:生成 Bootstrap 样本 2.3 重抽样:生成 Bootstrap 样本用到 rsample包,生成 5000 个 Bootstrap 样本: library(rsample) set.seed(12345) bs = bootstraps(res, times = 5000) bs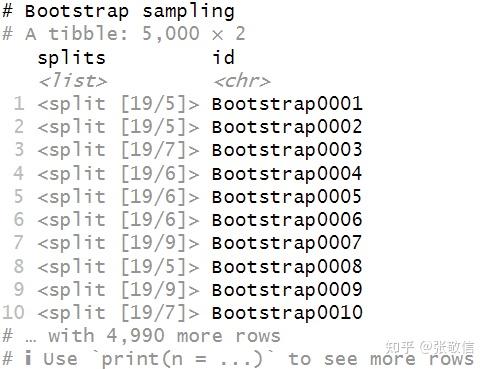 速度飞快,因为只是创建引用,并不真的操作数据。 19 就是每次可重复抽样到的观测数量,也是后续要使用的分析数据;5,5, 7,。。。是每次未被抽到的观测数量(可用作测试和验证,本例不需要它们)。 接着是取出数据,用到 analysis()提取分析数据: bs = bs %>% mutate(data = map(splits, analysis)) bs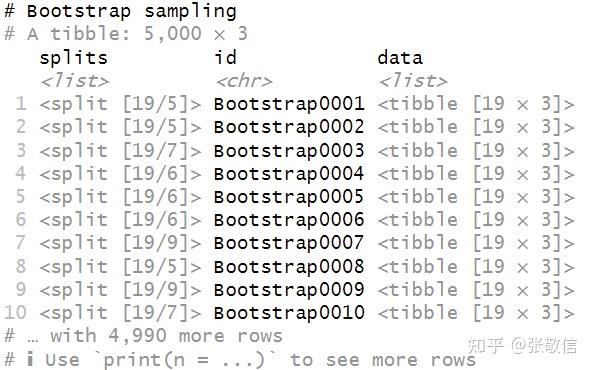 接着,第一列就不需要了,删掉;data数据列做展开: bs = bs %>% select(-1) %>% unnest(data) bs 至此,Bootstrap 数据就生成好了,再做计算: Y_{i, Boot} = Y_{i, Pred} + R_{rand} ,即把后两列加和,得到 boot 因变量,还需要自变量数据,把原始数据也连接进来: bs = bs %>% mutate(weightboot = resid + pred) %>% left_join(df, by = "ID") bs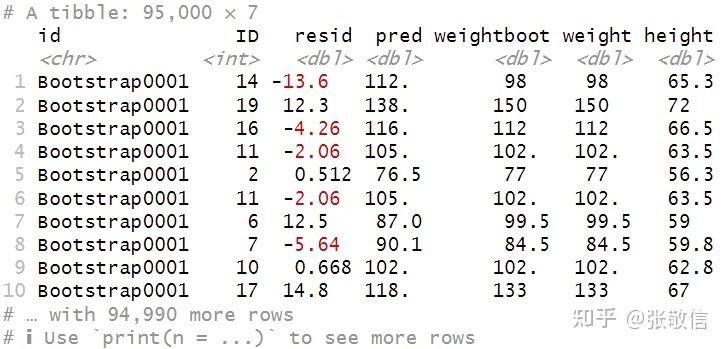 数据彻底准备完成! 以上是为了展示中间过程,正常管道衔接一步到位即可: bs = bootstraps(res, times = 5000) %>% mutate(data = map(splits, analysis)) %>% select(-1) %>% unnest(data) %>% mutate(weightboot = resid + pred) %>% left_join(df, by = "ID") 2.4 批量建模:每个 Bootstrap 样本,分别做回归,提取回归系数我的批量建模的文章已经很多了,细节不再赘述: rlt = bs %>% group_nest(id) %>% mutate(model = map(data, ~ lm(weightboot ~ height, .x)), coefs = map(model, coef)) %>% unnest_wider(coefs) rlt 这就完成了计算,这里关心的是两个回归系数,就是后两列。 2.5 探索Bootstrap分布,获取置信区间对于截距列: rlt %>% ggplot(aes(`(Intercept)`)) + geom_histogram(fill = "steelblue", color = "black") library(infer)
rlt %>%
select(id, `(Intercept)`)%>%
set_names("replicate", "stat") %>%
get_ci(level = 0.95, type = "percentile") library(infer)
rlt %>%
select(id, `(Intercept)`)%>%
set_names("replicate", "stat") %>%
get_ci(level = 0.95, type = "percentile") 对于斜率列height,同理可做(略)。 想写出这样简洁、优雅的代码,学习全网最新的 R 语言编程技术,掌握真正的数据编程思维: 更多内容参阅: 免费课件: |
【本文地址】